


Brain F*ck Programming Language: A Beginner's Guide
Learn the basics of this esoteric programming language with this easy-to-follow guide.


Introduction
First of all, before we look at the Brain F*ck Programming language, we need to first understand what an esoteric programming language is, as the brain f*ck itself is an esoteric programming language.
An esoteric programming language (also known as esolang) is a programming language that is created to be challenging, with some strange and unconventional syntax, and quirk behavior that makes them very different from traditional programming languages. They are mostly designed for experimentation, artistic expression or humor.
The brain f*ck programming language is an esoteric programming language with a very small instruction set, consisting of eight(8) commands only. It was created by Urban Müller in 1993.
It is designed to be as difficult as possible and is often used as a challenge to experienced programmers.
The language is stack-based, that is it stores data on the stack.
The Syntax of Brain F*ck
The Brain F*ck esoteric programming language has just eight (8) commands, and these commands are:
| Commands | Function |
> | Increment the data pointer by one (to point to the next cell to the right). |
< | Decrement the data pointer by one (to point to the next cell to the left). |
+ | Increment the byte at the data pointer by one. |
- | Decrement the byte at the data pointer by one. |
. | Output the byte at the data pointer. |
, | Accept one byte of input, storing its value in the byte at the data pointer. |
[ | If the byte at the data pointer is zero, then instead of moving the instruction pointer forward to the next command, jump it forward to the command after the matching ] command. |
] | If the byte at the data pointer is nonzero, then instead of moving the instruction pointer forward to the next command, jump it back to the command after the matching [ command. |
Before we go into the practical use of the syntax of this programming language, we will have to first look at how the memory of a computer system works, as that will give us the basis for writing programs in this language.
You will agree with me that the lowest unit of memory of a computer system is called a bit. And a bit is either 0 or 1. And if you understand number bases, you will realize that having just 0 and 1, which are two numbers only, we can say that a bit can take only binary numbers (base two) that is 0 and 1.
Furthermore, we have the next unit of memory after bits, which is bytes, a byte is made up of 8 bits. And remember that a bit is in base 2, so for us to get the total number of data that can be stored in a single byte, we will have to get the range from 0 to 8 of base 2.
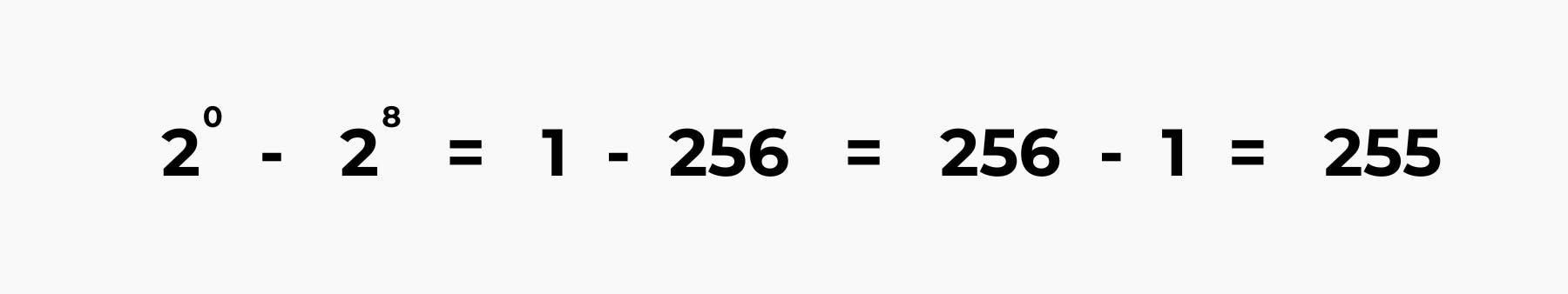
So from the image above, you will see that for a byte, we have a range from 1 to 256, which the actual number that a byte can contain will be the higher number minus the lower number that can be contained in the byte, which will give us 255.
So why did we have to go through this route all to explain the Brain F*ck esoteric language?
It is simply because it is the foundation upon which the esoteric language, Brain F*ck is built.
It makes use of cells, with each cell being able to carry a byte of data, now this byte of data that is used by the Brain F*ck is the ASCII (American Standard Code for Information Interchange). Each cell that can carry a byte can contain one of any of those codes in the ASCII. Please make sure you go through the ASCII manual and understand how to use it, with a focus on the Des and the Char column on the table.
Here is the compact version, which can also be found on the ASCII manual page:

To read the table, you first all read the role, then the column, For instance, let's say we need to get the value G, we simply need to look at the column G falls under, here it is the column with the value 70 and then next we check for the row which G belongs to, and you will observe that it is 1, add these two values together, we will have 71, that is to be able to get G, we will have to store the ASCII code 71 in a Cell.
The Brain F*ck Cell
The esoteric programming language makes use of a cell, with each cell having the ability to contain characters from 1 to 256, making it a total of 255. But since it makes use of the ASCII table, you might find only from 1 to 128 useful (that is 127 characters), as that is how far the ASCII table goes.
When you start writing the Brain F*ck, what you have is a series of cells, each of them initialized with zero, which in the ASCII cell is given to be null, in other words empty.

The Data Pointer
This is one of the most important concepts in the esoteric language, there is always a pointer available pointing at the first cell of the language, ready to carry out any operation given to it based on the commands given to it. Remember that a cell can only hold a single character, so in essence, the pointer points to a cell holding a single data at a time.

And you only have one pointer to work within your brain f*ck program. Every command carried out in this language will be based on the position of this pointer.
The Increment Command (>)
One of the commands we have is the increment command, which is represented with a greater than sign. It can also be referred to as the shift right command.
What this command does is move the pointer from one cell to another cell by moving it from the present position to the next cell by the right. One good thing is that we can move it multiple times depending on the position of the cell we want to access.

This is how to move across cells incrementally, that is from one to another progressively.
The Decrement Command (<)
This is another command, it is the opposite of the Increment command, it has a syntax of a less than sign, <, it is also referred to as the shift left command.
This moves the pointer from the present position it is to the previous cell, or the cell before it. Just like the Increment cell, it can also move across cells multiple times in a retrogressive way.

This is a simple illustration to show the decrement across the cells.
The Plus Command (+)
This command increments the byte at the cell the data pointer is presently pointing at. For every increment, it adds one to the byte, remember, the cells are initialized with 0 which for every increment, we have one added, and the number in the cell is the representation of the corresponding code based on the ASCII.
Here is a pictorial representation of the process

Just like the other commands, you can use the plus command (+) multiple times.
Let us now combine the Increment, decrement and the plus command/syntax.
Let's say we want to have 3 in the first cell, 5 in the second cell and 1 in the third cell, we are going to have something of this nature:
First, we will use the add command three times to have 3 in the first cell.

Secondly, we will move our data pointer to the next cell by using the increment command once to go to the second cell, which is the next cell from the first cell.

Next, we will increase the bytes in this cell by 5, which we will have to use the plus command 5 times:

Thirdly, we will have to move to the third cell, and we will do that by incrementing our data pointer, using the increment command:

Finally, we are going to increase the byte of the third cell by 1, which means we are going to use the plus sign one time:

The Minus Command (-)
This command decrements the byte at the cell the data pointer is presently pointing at. For every decrement, it subtracts one from the byte, Remember, the cells are initialized with 0, so this command is used on a cell that already has an existing value other than 0.
Using the last example above, let us remove two from the first cell:
To do this, we first have to move our pointer from the third cell to the first cell by moving backward using the decrement command two times, since the first one will move it backward from the third cell to the second cell, and the second one will move it from the second cell to the first cell:

Next, we will reduce the byte in the first cell to 1, which means we will have to use our minus command two times, as the first one will reduce it to 2 and then the second one will reduce it to 1.

This is how to apply the subtract command.
Standard Output (stdout) Command (.)
This is the command that is used to output or print out the byte contained in the cell at which the data pointer is presently pointing. The syntax is a full stop. Remember that the byte that will be printed to standard output will be its ASCII equivalence.
Let us take, for example, we have a cell with the number 10, What will be printed to the stdout is the newline character ('\n'), as that is the ASCII equivalence of 10 and also to printout 'A', we need to increment the byte in the cell to 65, as that is the code that represents 'A' in the ASCII table.

Standard Input (stdin) Command (,)
This is the command that takes input as a byte from the standard input and stores it in the cell which is currently pointed by the data pointer. The syntax is a comma, and one can also print out what He/She inputs immediately by using the stdout command (.). One good thing about taking input using this command is that it will take the character you input as an ASCII, and then convert it to a decimal to be stored in the cell, so while printing it out, it prints out the ASCII equivalent of it. Remember that you can only enter one character per cell, so even for numbers, you can only store a single digit, if you enter more than a single character, only the first one will be stored, and the rest will be discarded.

The Looping Commands ([ ])
Although others might call them by other names, I tend to name them after their function, the syntax for this command is two square brackets, as each one can't be used independently of another, they are always used together.
What the [ does is to guide against the ], and what the [ does is to guide against the ].
The [ checks if the byte the data pointer is currently pointing at is zero if it is then jump it to the next operation or instruction that is stated after the ].
And the ] checks if the byte the data pointer is currently pointing at is non-zero, then instead of jumping it to the next command, take it back to the command/instruction immediately after the [.
So in essence, the instructions before the [ should be one that will initialize the count, that is the number of times the instructions after the [ should be executed, and since the number of times the instructions after the [ will be run depends on the count before it, then there is a need to decrease that count for each time the code after the [ is run to avoid running into an infinite loop.
So that once the count is decreased to zero, then the execution will move outside the closing bracket ], executing the instructions that come after the closing bracket.
To understand this much better, let us look at a situation where we want to increase the byte of a cell to 65 and then print the value, which based on the corresponding ASCII code, we will be printing out 'A'.
One way of doing this is by using our add command (+) 65 times or taking advantage of the Loop command.
So let us first start by looking at the normal traditional way of doing this:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

So using the increment command 65 times will give us the value of 'A'.
Now let us look at a much better way of achieving this same result. We are to find two numbers which when we multiply them, we will get either something close to 65 or the 65 itself. If you observe closely, you will see that 5 x 13 will give us 65.
So now we just need to count 13 5 times and we will have what we have, alternatively, we can also decide to count 5 13 times, and we will still achieve the same result. And that is where the loop comes in.
We will be going over this in Steps.
Step 1: Initialize it with a count, in this case, I am going to use 5 and because of how the loop commands work, they only check against a zero value, so your count should start from the very number you want to count in.
+++++

Step 2: Now we want to begin our loop, We will do that by opening our square bracket.
+++++[

Step 3: We will move to the next cell, as we want to still retain our count in the first cell.
+++++[>

Step 4: We will set the number we want to loop over, here it is 13 because that is what we want to count five times so that we can get the ASCII code 65 as that will translate to 65.
+++++[>+++++++++++++

Step 5: Since we have run the Instruction we want to loop over for the first time, it means that we need to reduce the number from 5 to 4, so to do that, we will have to move back to the first cell which is holding our count.
+++++[>+++++++++++++<

Step 6: We will now reduce the count by one, as we have run the loop one time so that we will be left with 4.
+++++[>+++++++++++++<-

Step 7: We will have to close our loop so that it will have a guide against going outside the instruction inside the square brackets when the value before the square bracket is nonzero, in order words, when our count is not yet zero. 13 is added to the byte count of the second cell, and byte in the first cell reduces by 1, from 5 to 4.
+++++[>+++++++++++++<-]

Step 8: This code goes again and runs for the second time, that it goes through steps 3, 4, 5, 6 and then 7. This time around it increments the byte count of the second cell from 13 to 26 and reduces the count of the first cell from 4 to 3.

Step 9: The code runs again for the third time, it goes through steps 3, 4, 5, 6 and then 7. This time around it increments the byte count of the second cell from 26 to 39 and reduces the count of the first cell from 3 to 2.

Step 10: The code runs again for the fourth time, it goes through steps 3, 4, 5, 6 and then 7. This time around it increments the byte count of the second cell from 39 to 52 and reduces the count of the first cell from 2 to 1.

Step 11: Finally, the code runs the fifth and final time, it goes through steps 3, 4, 5, 6 and then 7. This time around it increments the byte count of the second cell from 52 to 65 and reduces the count of the first cell from 1 to 0.

Step 12: Now we have a zero value in our count and for that the opening square bracket [ will guide against the code executing the instructions inside the bracket again, it will make it jump over to the next set of instructions that is defined after the closing square bracket ]. So since what we want to print out is the byte in the second cell, presently we are in the first cell, we need to go to the second cell since that is the cell containing the byte we want to print.
+++++[>+++++++++++++<-]>

Step 13: Since our data pointer is now pointing to the cell whose byte we want to print out, we just use our print command to display the corresponding ASCII value to the standard output, which here is 'A'.
+++++[>+++++++++++++<-]>.

With this, we have saved ourselves the stress of having to use our plus command (+) 65 times to achieve the same result.
How to Write Programs in Brain Fuck
Installing the Brain Fuck Interpreter
To write a program in brain fuck, we first need to install the brain fuck interpreter. You can search on the internet for brain fuck interpreters as there are quite a number of them, some of which are written in C, python, JavaScript etc.
If you are using a UNIX-based (Linux) Debian-based(Ubuntu, Linux Mint, Kali Linux etc.) operating system, then there is one that is just right for you. You can download it here. You can download and install any of the published versions of your choice.
After installation, you can simply check if it installed successfully by running any of the two commands on your terminal:
which bf
This command shows you the location where the executive for the interpreter is installed.
bf
This shows you some things about the interpreter, the version and some other information.
If you are using any other operating system and can't find the interpreter for your operating system, you can simply search for online brain fuck interpreters and take advantage of them as they will also give you the same result as the ones that runs directly on your local machine.
Creating a Brain Fuck Language File
The brain f*ck esoteric language file also has a format just like Python (.py), JavaScript (.js) etc. You can either format it as (.bf) or (.b) any of them will do the work.
So to begin to write brain fuck code, the files need to be named with a .bf or .b format. Any text editor can be used. In our case, I will be making use of VIM for writing the source code.
Examples of Brain F*ck Programs
Since we have talked extensively about brain fuck as the whole, the commands and what each of them does, so we will be looking at some examples of programs that are written in brain fuck, now starting with the first and obvious one which is more common in other programming languages, "hello world".
Example 1: Hello World
We will be writing 'hello world' using the brain fuck esoteric language. To make things easier, we will be doing that using the step-by-step approach.
There are various ways we can do this, one of them is to make use of a single cell to write and print, that is as we write the byte, we print it out, continuously till we are done, which to me is a better way.
The other way is to write every one of the bytes in their cell, and then either print the cell as we write to it or first of all write to all the cells and begin to print the byte stored in the cell one after the other.
So we are going to use the first approach to print 'hello' and then the last approach to print 'world'.
First Approach: hello
Step 1: We will first have to check for the corresponding decimal value of 'h' in our ASCII table, which is 104, so we will need to increment the cell our data pointer is currently pointing at, which is the first cell by the add command (+) 104 time.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++
Step 2: Next we will print it out using the print command (.).
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.

Step 3: Since we are using the same cell to print the next letter, which is 'e', the ASCII code for that is 101, so if you check, from 104 which is the byte the data pointer is presently on to 101 is a difference of 3, so we will need to reduce the byte by 3 to get to 101 and then we will print it out.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.---.

Step 4: Next, to print the next character, which is 'l', the ASCII code for 'l' is 108, which is 7 ahead of the byte that is presently in our cell, so we will have to increase the byte from 101 to 108 and then print it out.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.---.+++++++.

Step 5: Next, to print the next character, which is 'l' again, the ASCII code for 'l' is 108, which is the byte that is presently in our cell, so what we need to do is just print it out again.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.---.+++++++..

Step 6: Next, to print the next character, which is 'o', the ASCII code for 'o' is 111, which is 3 ahead of the present byte in the cell, so we will need to add 3 to 108 and then print it out.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.---.+++++++..+++.

Step 7: Lastly, let us print a SPACE, so that we will start by printing 'w' using the second approach. The ASCII code for SPACE is 32. So from where we are now which is 111, to get to 32, we will need to remove about 79 from 111 to get to 32. And then we will print it out.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.---.+++++++..+++.
-------------------------------------------------------------
------------------.


Let us run the code and see what we are going to get:

So you can see that we got hello and a space after by running our code with the brain fuck interpreter, bf.
Second Approach: world
In this second approach, every data/byte will have its cell. So to print world, each cell will carry the ASCII code for each word, so we will be using 5 cells in total.
Step 1: We will first have to check for the corresponding decimal value of 'w' in our ASCII table, which is 119, so we will need to increment the cell our data pointer is currently pointing at, which is the first cell by the add command (+) 119 time and print it.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.

Step 2: We will check for the corresponding decimal value of 'o' in our ASCII table, which is 111, so we will need to first move to the next cell using our increment command (>) and then increment the cell our data pointer is currently pointing at, which is the second cell by using the add command (+) 111 times and print it.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++.

Step 3: The corresponding decimal value of 'r' in our ASCII table, is 114, so we will need to first move to the next cell using our increment command (>) and then increment the cell, which is the third cell by using the add command (+) 114 times and print it.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++.

Step 4: The corresponding decimal value of 'l' in our ASCII table, is 108, so we will need to first move to the next cell using our increment command (>) and then increment the cell, which is the fourth cell by using the add command (+) 108 times and print it.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++.

Step 5: The corresponding decimal value of 'd' in our ASCII table, is 100, so we will need to first move to the next cell using our increment command (>) and then increment the cell, which is the fifth cell by using the add command (+) 100 times and print 'd' which is the last character in the word 'world'.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++.

Bonus: The corresponding decimal value of newline in our ASCII table, is 10, so we will need to first move to the next cell using our increment command (>) and then increment the cell, which is the sixth cell by using the add command (+) 10 times and print newline (\n) which will print a newline after printing the word 'world'.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++.
>++++++++++.


Let us now run our code and see the result:

So we can see that we have the word world followed by a new line.
We can print the word hello world by combining the code for hello and that world together, Note that you will need to move to the next cell after printing the word hello, before adding the code to print the word world.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++.---.+++++++..+++.
-------------------------------------------------------------
------------------.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++++++++++.
>++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
++++++++++++++++++++++++++++++++++++++++.
>++++++++++.


Example 2: Hello World
For this example, we are going to still be printing hello world, but this time around in a more optimized way, we are going to be taking advantage of the loop commands.
We will be doing this in steps:
Step 1: Check for two numbers that when we multiply, we will get exactly the ASCII Decimal code for 'h' or something close to that. Now if you look properly, the number for 'h' is 104, to get to 104 we can say that 8 x 13 will give us 104, so we can pick it up from there.
Step 2: We will loop 13, 8 times using our loop, I believe from the example of using a loop earlier in this article, you should have an idea of doing that, so we are going to have:
++++++++[>+++++++++++++<-]>.
This one will give us the 104 which is the character 'h'.
Step 3: To get 'e', the code is 101, so to move to 101 from 104, we will reduce the byte in the present location by 3 and then print it out.
++++++++[>+++++++++++++<-]>.---.
Step 4: To get 'l', the code is 108, so to move to 108 from 104, we will increase the byte in the present location by 4 and then print it out.
++++++++[>+++++++++++++<-]>.---.+++++++.
Step 5: To get the second 'l', since we are already at the location of 'l' which is 108, we just need to print out the value again:
++++++++[>+++++++++++++<-]>.---.+++++++..
Step 6: To get 'o', the code is 111, so to move to 111 from 108, we will increase the byte in the present location by 3 and then print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.
Step 7: To get the next character, which is SPACE, the code for SPACE is 32, so to move to 32 from 111, we will have to decrease the byte in the present location by 79 which will result in too many minus command character being used, so to solve this, we can employ our loop command, we just need to check for two numbers that when we multiply, we will get exactly or something close to 79.
We will have 13 x 6 which will give us 78, then plus 1 which will give us 79.
So let us execute this using our loop, first, we need to get to the next cell, then initialize it with 6, so that we will be able to run the command inside the loop which would be subtracting 13 from the cell that presenting has a byte of 111, 6 times, which would be the same thing as subtracting 13 6-times, which would be subtracting a total of 78 from 111, which will give us 33.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++
Step 8: We will define our loop, we want to subtract 13 from the previous cell, that is the cell with 111, so we will first move back our data pointer to that cell from the present cell which we initialized with the number of times we want to perform that subtraction. Then we subtract 13 from the cell, which is done with the minus command. Then we move to the next cell, which is the cell that holds the number of times we are to loop, and then decrease it by one.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]
Step 9: Now once our loop finishes, we would have subtracted 13 x 6, which is 78 from the byte that was in the cell before (111), which will give us 33, but what we need is 32, which means we need to subtract 1 from the 33 to get our desired 32.
So since we are now at the cell we used to initialize our loop, we would move our data pointer one step backward and reduce one from the byte that is now 33 to get 32 which will give us a SPACE. Then we display it using the stdout command.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
Step 10: Next, we will print the character 'w', the ASCII code for 'w' is 119, so to get 119 from the byte in the present cell, we will need to add 87 to 32. Now using a loop, we need to find two numbers whose multiplication will give us 87 or close to 87.
If we look closely, 5 x 17 will give us 85, then we can add 2 to 85 to give us 87. We will first move to the next cell, then initialize the loop with 5.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++
Step 11: Next, we will start our loop by moving our data pointer backward one time, to point to the cell with 32, and then add 17 to it. After which I would move the data pointer forward to the next cell carrying our number of loops, and reduce the number of loops by 1.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]
Step 12: After the loop has finished running, we will be at the Cell of our number of loops is initialized, which will be zero, we will have to move backward to the previous cell, which by now would be carrying the number 117, but our target is to have 119, so we just need to add 2 to it and print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.
Step 13: Next, we will print 'o', whose code is 111. To get to 111 from 119, we simply need to subtract 8 from 119 and print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.
Step 14: Next, we will print 'r', whose code is 114. To get to 114 from 111, we simply need to add just 3 to 111 and print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.+++.
Step 15: Next, we will print 'l', whose code is 108. To get to 108 from 114, we simply need to subtract 6 from 114 and print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.+++.------.
Step 16: Next, we will print 'd', whose code is 100. To get to 100 from 108, we simply need to subtract 8 from 108 and print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.+++.------.--------.
Step 17: Finally, we will print the newline character ('\n'), The newline code is 10. To get to 10 from 100, we simply need to subtract 90 from 100 and print it out.
So we will need to make use of loops here. First, we look for two numbers we can multiply to either get 90 or something close to 90. If we look at 10 and 9, 9 x 10 will give us 90, so let us first move to the next cell and initialize the loop with the value 9.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.+++.------.--------.
>+++++++++
Step 18: Next, we need to subtract 10 from our cell that carries 100 currently, and what the loop will do is run it 9 times, which will be the same thing as subtracting 90 from 100 to give us our desired 10.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.+++.------.--------.
>+++++++++[<---------->-]
Step 19: For the final step, since we are presently in the cell that we used to initialize our loop, to get our new line, we need to move backward to the cell containing our new line, and then we print it out.
++++++++[>+++++++++++++<-]>.---.+++++++..+++.>++++++[<------------->-]<-.
+++++[<+++++++++++++++++>-]<++.--------.+++.------.--------.
>+++++++++[<---------->-]<.


This is the output we have. So with loops, we were able to get the same results but with fewer number of the Brain F*ck commands.
Exercise:
Write your name using the same concept, you can try it in both uppercase letters and Normal Case Letters.
Conclusion
There are other aspects of Brain Fuck Programming such as the mathematical aspect that has to do with addition, subtraction, division, multiplication and others, but for this article, our goal is to cover the basics in such a way you will find it easy to grasp and understand, an article on the arithmetic part will come in much later.
Thank you for reading. You can connect with me on Twitter and LinkedIn.