


What Happens When You Type "https://www.google.com" in Your Browser and Press "Enter"
Understand The Processes Involved in Browsing a Web Page.


Introduction
One beauty of the internet is that, you can make use of it even without the knowledge of the technologies that power it.
Many people understands the internet just from the perspective of searching and getting information and resources such as: music, videos, documents, images etc. from various websites, blogs and searches. But they never really care to understand the processes that are involved from them visiting or searching a website using their devices (phones, computers etc.) to them receiving a response of what they searched for.
So this article is to help this class of people understand the processes involved from when you do a google search to when you get the results of what you searched for.
What are the Processes?
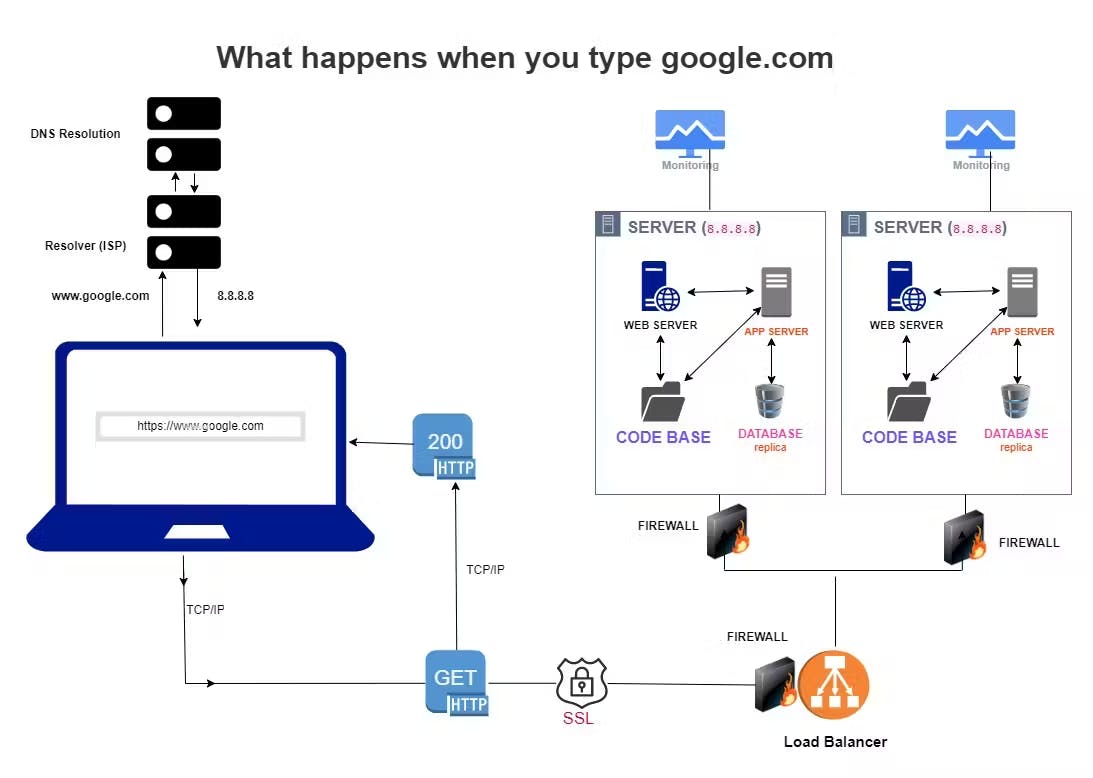
As you type https://www.google.com on your browser and press enter, what you are doing at that moment is that you are sending an HTTP Request from your Device, at this point, your device can be referred to as the Client.
DNS Request Process
Immediately after making this request, a DNS (Domain Name Service) Request is sent, this is because for your device to be able to locate https://www.google.com on the internet, it first needs to know the IP (Internet Protocol) address of the https://www.google.com, as that is how devices (Computers, Phones, Gadgets etc.) are identified on the Internet. So without an IP address, a device can not browse nor have access to the internet, nor can it communicate with other devices. So after pressing enter, your device is literally trying to connect and communicate with another device at the other end, this time around this device it is trying to connect to is called a Server. It needs the IP Address of the server to be able to get information from Google, since the Google is contained in the Server. This is just like how one will need to know the address of your house to be able to locate you, since you are literally staying inside the house. So also, your device needs to know the IP address of where google.com is stored, which in this case is in the Server. This IP Address are of two types, there is the IPv4 (which is called the IP version 4) and the IPv6 (which is called the IP version 6). The IPv4 is a string of decimal numbers, separated by a dot, these numbers are grouped in 4, with each group separated by a dot. This is an example of an IPv4 address (192.168.0.1) you can see that we have four different groupings, that are separated by a dot. There is also the IPv6, which is a string of Hexa-decimal numbers, this one are grouped in eight, with each group separated by a colon. An example of this is (FE80:CA00:0000:0CDE:1257:0000:311F:259D).
To resolve the IP of where Google is located, a DNS Request will be sent, whose work is to dig up the IP address of Google from the domain name, since the IP of any website is always mapped to the Domain Name via the A records (for IPv4) or AAA records (for IPv6). So after getting the IP address, let us say in this case it is 172.217.193.104, it then returns this IP address back to your browser application, now your browser application will be able to comfortably locate the particular computer in which Google is been hosted on the internet.
The TCP/IP Process
After getting the IP Address of the domain name, your device (computer or phone browser) can not just go ahead to access the IP Address of Google casually, it has to do that following some set of rules, called the TCP (Transmission Control Protocol)/IP (Internet Protocol). And why this is important is that there are various hardware (computers, gadgets etc.) and Software (Browsers, Email Clients etc.) that are involved in communication over the internet, thus, the need to set a standard between them, a standard of how messages should be sent and received between computers that are connected on the internet, so that there won't be an hassle between these devices irrespective of their differences in their underlying technology. This TCP/IP is responsible for ensuring that your request, which is the www.google.com is transmitted to the appropriate destination. So it is safe to say that the TCP/IP takes precedence from the point you send an HTTP Request, to the point you get back an HTTP Response.
The HTTP/SSL Process
Before your request gets to the IP address of Google, it is encrypted using the HTTP/SSL (HyperText Transfer Protocol/Secure Shell Layer), this SSL comes in the form of a certificate which helps to secure whatsoever messages you are sending as a HTTP Request over the internet, it takes the message and encrypts it, in such a way that even if the message is to be intercepted along the way by another person/party, they won't be able to understand nor make any meaningful use of the information. This is to safe guard information, which might contain very sensitive information like credit card details or some private information which the sender would want to keep private.
The Firewall
Once the HTTP Request gets encrypted, it goes straight to the Load Balancer, the Load balancer in this case is secured with a Firewall, and this firewall could be a software or an hardware. For the software type, one of the common available ones that comes by default with the Ubuntu Server is called the UFW (Uncomplicated Fire Wall). This Firewall helps to filter both incoming and outgoing connections, and either allows or block connections based on how it is been configured to. Although this is not the only security measure that is being put in place, howbeit, it is one of the most basic and yet important security apparatus that is put in place to prevent some malicious attacks and filter out contents that are not needed either in the request or the response.
The Load Balancer
Given how big Google are, and how many persons all over the world makes use of Google as their search engine to search for information of various kinds and sorts, it is only natural for them to witness a huge number of request from millions if not billions of people all over the world that needs to be processed within seconds, as such there is a high possibility of them using more than a single server to respond to each requests made by these people. Thus, the need for Load Balancers, these load balancers can be a hardware, or a software. What this Load balancer does is to distribute the incoming requests to different servers depending on how it is being configured to do that. It uses an algorithm to do so. Most times a combination of two or more of these algorithm is used on the Load Balancer to improve it's efficiency in distributing the connections to the servers. An example of a common software-based load balancer is the HAProxy. By having a load balancer to distribute connections, it helps eliminate a SPOF (Single Point Of Failure). Due to one or two servers shutting down or having issues. Another thing is that there is a very high possibility of them having more than one Load Balancer to eliminate a SPOF due to the load balancer shutting down or having issues and unable to function.
As the load balancer distributes requests to different servers, each of those servers are secured with a firewall. This is also to filter incoming request and outgoing response, to me I will say it's more like a double authentication, that is whatsoever thing that escapes the firewall securing the load balancer, get to face the firewall securing the servers as well.
The Servers
Next, we have the servers, These Servers can either be a Physical computer or instances of the virtualisation of a computer. They can be at any place around the world, mostly in a data centre. These computers are mostly without screen, thus they can only be accessed through a secure shell, like the ssh. These servers can be configured the same way as they will be serving the same function. So each server contains a Web Server, an Application Server, a Database and also a Code Base.
The Web Server, Application Server, Database and Code Base
The Web Server, Application Server. Database and Code Base are connected in such a way that when your HTTP Request gets to any of the servers, what happens is that it first goes through the web server, as that is what processes HTTP Request, and as it goes through the Web Server, it processes it based on your request. If what you requested for is a Static HTML page, it will just go straight to the Code Base, get the particular static page and send it to you as an HTTP Response. The code base usually contains all the web resources that is used by the website/webpage, resources such as HTML Pages, CSS and JavaScript files, images, videos, documents etc.
If the content is a dynamic content, that is a content that changes based on the information that is provided along with the incoming request, then from the web server, it is sent to the application server. The application server here deals with anything that has to do with business logic, calculations etc. For example let's say you are in an online store, shopping, by adding items to your cart, you will observe that the prices of those items you are adding keeps reflecting in the total amount of items you are about to purchase, that is application server in real time, doing all of the calculations. Most times the application server actually depends on information stored in the Database, so it goes to the database, pick what it needs, and process it based on the code base available. The code base here contains instructions on how the application server should process business logic and calculations, it then send the processed or dynamic content to the web server at the same time store it in the database whenever it is necessary. It sends the processed information to the web server because it is still the duty of the web server to send a Response to the client (your device). Sometimes there are application servers that can also serve web pages directly and also there are web servers that can carry out the function of an application server.
The database across all the servers are all replicas, thus all of them contains the same records and such records are shared/synchronised amongst them so that everyone's records will be available to any of the servers for processes whenever a request from a client is been directed to any of the servers. There is also a Master Database that contains all the records from the other Database. This master Database is serving more like a backup database, in case any of the database at anytime develop any fault or issues, the data can easily be restored without any data loss.
Each of these Servers are connected to a monitoring device which oversees the health and state of operation of these servers, that helps the engineers to know when to shutdown or delete and redeploy another server in case of a server failure, or how to fix a server whose efficiency has dropped etc.
Finally, based on your request, which is the https://www.google.com, a response will be sent back to you in form of an HTML page when the information which you requested for is found, your browser then takes the HTML file and displays it to you as a web page or website on your device (computer, phones, smart TV etc.). And if the information in which you requested for is not found, it returns an error message, letting you know that the page you requested for is not found or missing or restricted.
These are all the underlying processes that are involved whenever you type https://www.google.com or any other website in any browser on your device and press enter.
Conclusion
It is of important to know that the setup used in explaining all the processes involved in making a HTTP Request to receiving a HTTP Response, can defer depending on the website that is being built, it's requirements and targets. However, this is one of the bare minimum for running a website/webpage that process quite some amount of traffic in a short period of time.
Thank you for reading. You can connect with me on Twitter and LinkedIn.
The picture of the web infrastructure setup above that is used to explain the processes involved in making a request and getting a response is credited to Dr. Engr. Ehoneah Obed, which is a graduate of ALX Software Engineering.